Bem-vindo de volta ao nosso curso de 30 dias sobre AWS, onde exploramos o complexo mundo da computação em nuvem.
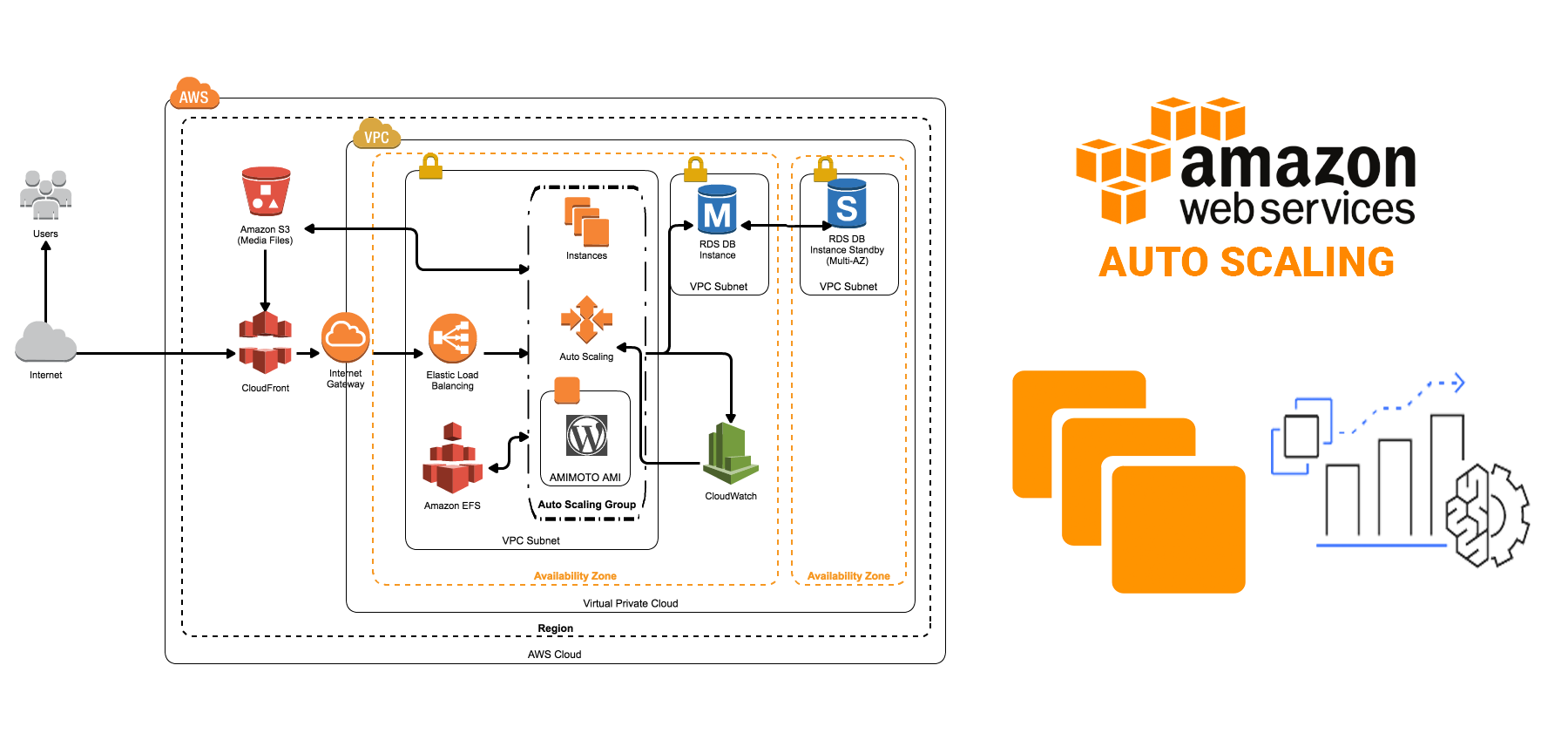
Hoje, vamos explorar o Autos Scaling, um recurso fundamental da AWS que garante que a suas aplicações possam lidar com cargas variáveis de maneira eficiente.
Confira as perguntas e respostas de entrevista baseadas em cenários no final deste paper para ajudá-lo em entrevistas!
Visão Geral do Auto Scaling e Seus Benefícios
Vamos nos aprofundar na visão geral do Auto Scaling e explorar seus benefícios em mais detalhes.
Visão Geral do Auto Scaling
Auto Scaling é uma funcionalidade fundamental fornecida pela AWS que permite ajustar automaticamente o número de recursos de computação em sua aplicação com base na demanda. Ele funciona monitorando as métricas de carga da sua aplicação e ajustando dinamicamente a capacidade para manter um desempenho estável e previsível ao menor custo possível.
Como Funciona o Auto Scaling
- Monitoramento de Métricas: O Auto Scaling monitora continuamente métricas de desempenho chave, como utilização da CPU, tráfego de rede ou métricas personalizadas definidas pelo usuário.
- Políticas de Escalonamento: Com base em políticas de escalonamento predefinidas, o Auto Scaling determina quando adicionar mais instâncias (escalar para fora) ou remover instâncias (escalar para dentro) para atender aos requisitos de capacidade desejados.
- Integração com Serviços AWS: O Auto Scaling integra-se perfeitamente com outros serviços da AWS, como Elastic Load Balancer (ELB) e CloudWatch, para criar uma arquitetura robusta e escalável.
Benefícios do Auto Scaling
- Alta Disponibilidade: O Auto Scaling distribui instâncias em várias Zonas de Disponibilidade (AZs) para garantir alta disponibilidade e tolerância a falhas. Em caso de falha em uma AZ, o Auto Scaling lança automaticamente instâncias em outra AZ para manter a disponibilidade do serviço.
- Otimização de Custos: Ao ajustar dinamicamente o número de instâncias com base na demanda, o Auto Scaling ajuda a otimizar os custos, escalando para dentro durante períodos de baixa atividade e escalando para fora durante picos de carga. Isso garante que você pague apenas pelos recursos necessários, minimizando despesas desnecessárias.
- Melhoria de Desempenho: O Auto Scaling ajuda a manter um desempenho consistente ajustando automaticamente os recursos para acomodar mudanças na demanda. Ele garante que sua aplicação permaneça responsiva mesmo durante picos súbitos de tráfego.
- Tolerância a Falhas Aprimorada: Com o Auto Scaling, as instâncias são distribuídas em várias AZs, reduzindo o risco de um único ponto de falha. Se uma instância ou AZ se tornar indisponível, o Auto Scaling redistribui automaticamente o tráfego para instâncias saudáveis, garantindo serviço ininterrupto.
- Flexibilidade e Escalabilidade: O Auto Scaling permite escalar sua infraestrutura para cima ou para baixo rapidamente em resposta a padrões de carga variáveis. Ele proporciona a flexibilidade de lidar com diferentes níveis de tráfego sem intervenção manual, permitindo que sua aplicação escale perfeitamente à medida que seu negócio cresce.
- Gestão Automatizada de Recursos: Ao automatizar o provisionamento e gestão de recursos, o Auto Scaling simplifica operações e reduz a sobrecarga associada ao escalonamento manual. Ele permite que você se concentre no desenvolvimento de suas aplicações em vez de gerenciar infraestrutura.
Implementando Grupos de Auto Scaling
Implementar grupos de Auto Scaling é um aspecto crucial para gerenciar aplicações escaláveis e tolerantes a falhas na AWS. Vamos nos aprofundar no processo de configuração e implementação de grupos de Auto Scaling:
1. Criar Configuração de Lançamento
- Comece criando uma Configuração de Lançamento, que define as configurações das instâncias lançadas pelo grupo de Auto Scaling. Essas configurações incluem a Amazon Machine Image (AMI), tipo de instância, par de chaves, grupos de segurança e qualquer dado de usuário necessário para inicializar as instâncias.
- Você pode especificar a configuração por meio do Console de Gerenciamento da AWS, AWS CLI ou SDKs da AWS.
2. Configurar Grupo de Auto Scaling
- Depois que a Configuração de Lançamento estiver definida, configure o próprio grupo de Auto Scaling.
- Especifique o número mínimo, máximo e desejado de instâncias no grupo. A capacidade desejada indica o número de instâncias que devem estar em execução a qualquer momento.
- Configure políticas de escalonamento com base em gatilhos predefinidos, como utilização da CPU, tráfego de rede ou métricas personalizadas do CloudWatch. Essas políticas determinam quando o Auto Scaling deve adicionar ou remover instâncias para manter a capacidade desejada.
3. Definir Políticas de Escalonamento
- O Auto Scaling permite definir políticas de escalonamento que ditam como o grupo deve escalar para dentro ou para fora com base nas condições especificadas.
- Por exemplo, você pode criar uma política de escalonamento que adicione uma instância quando a utilização média da CPU ultrapassar 70% por um período especificado.
4. Verificações de Saúde
- Configure verificações de saúde para monitorar a saúde das instâncias dentro do grupo de Auto Scaling. O Auto Scaling pode substituir instâncias não saudáveis automaticamente para manter a capacidade desejada e garantir alta disponibilidade.
- As verificações de saúde podem ser baseadas em verificações de status do EC2 ou métricas personalizadas relatadas ao CloudWatch.
5. Marcação de Instâncias
- Atribua tags às instâncias lançadas pelo grupo de Auto Scaling para melhor organização e gestão de recursos. As tags podem ser usadas para alocação de custos, automação e identificação de recursos.
6. Política de Terminação de Instâncias
- Defina a política de terminação de instâncias para especificar quais instâncias o Auto Scaling deve terminar ao escalar para dentro. As opções incluem a instância mais antiga, a instância mais nova ou as instâncias mais próximas da próxima hora de cobrança.
7. Balanceamento de Carga Entre Zonas
- Opcionalmente, configure o grupo de Auto Scaling para usar balanceamento de carga entre zonas com Elastic Load Balancer (ELB). Isso garante que o tráfego seja distribuído uniformemente entre instâncias em várias Zonas de Disponibilidade, melhorando a tolerância a falhas e o desempenho.
Integrando Auto Scaling com Elastic Load Balancer (ELB)
Integrar Auto Scaling com ELB é uma estratégia poderosa para garantir alta disponibilidade, tolerância a falhas e escalabilidade para suas aplicações na AWS. Aqui está um guia detalhado sobre como integrar Auto Scaling com ELB:
1. Criar Elastic Load Balancer (ELB)
- Comece criando um Elastic Load Balancer através do Console de Gerenciamento da AWS ou usando comandos da AWS CLI.
- Defina a configuração do load balancer, incluindo ouvintes, protocolos, zonas de disponibilidade e verificações de saúde.
- O ELB distribui automaticamente o tráfego de aplicação recebido entre várias instâncias registradas nele.
2. Configurar Grupo de Auto Scaling para Usar ELB
- Na configuração do Auto Scaling, especifique o ELB ao qual as instâncias devem ser registradas.
- Ao definir ou atualizar o grupo de Auto Scaling, forneça o nome ou ARN (Amazon Resource Name) do ELB.
- Isso garante que as instâncias lançadas pelo grupo de Auto Scaling sejam automaticamente registradas no ELB e se tornem parte do seu pool balanceado de carga.
3. Verificações de Saúde
- Configure verificações de saúde no ELB para monitorar a saúde das instâncias registradas nele.
- O ELB envia periodicamente solicitações de verificação de saúde para as instâncias e as marca como saudáveis ou não saudáveis com base em suas respostas.
- O Auto Scaling usa essas verificações de saúde para determinar o status de saúde das instâncias e substituir instâncias não saudáveis conforme necessário.
4. Balanceamento de Carga Entre Zonas
- Considere habilitar o balanceamento de carga entre zonas no ELB para distribuir uniformemente o tráfego entre instâncias em várias Zonas de Disponibilidade.
- O balanceamento de carga entre zonas ajuda a melhorar a tolerância a falhas e garante que o tráfego seja distribuído de forma eficiente, mesmo se uma Zona de Disponibilidade enfrentar problemas.
5. Ajustar Políticas de Auto Scaling
- Revise e ajuste suas políticas de Auto Scaling para escalar o número de instâncias com base em métricas e verificações de saúde do ELB.
- Por exemplo, você pode escalar para fora quando a contagem de solicitações por grupo alvo do ELB exceder um certo limite ou escalar para dentro quando a contagem de hosts saudáveis do ELB cair abaixo de um nível especificado.
6. Monitoramento e Métricas
- Monitore o desempenho e a saúde do seu ELB e do grupo de Auto Scaling usando o Amazon CloudWatch.
- Configure alarmes do CloudWatch para notificá-lo sobre quaisquer eventos de escalonamento, problemas de
desempenho ou falhas nas verificações de saúde.
- Utilize métricas do CloudWatch para analisar tendências, prever necessidades de capacidade e otimizar suas configurações de Auto Scaling e ELB.
Exemplo de Código com Boto3 para Criar um Grupo de Auto Scaling e Integrá-lo com ELB
Aqui está um exemplo de como usar o AWS SDK para Python (Boto3) para criar um grupo de Auto Scaling e integrá-lo com um Elastic Load Balancer (ELB). Certifique-se de ter o Boto3 instalado e configurado com credenciais da AWS.
import boto3
# Inicializar clientes Boto3 Auto Scaling e ELB
autoscaling_client = boto3.client('autoscaling')
elb_client = boto3.client('elb')
# Definir Configuração de Lançamento
launch_config = {
'LaunchConfigurationName': 'my-launch-config',
'ImageId': 'ami-12345678', # Especifique seu ID de AMI
'InstanceType': 't2.micro',
'KeyName': 'my-keypair',
'SecurityGroups': ['my-security-group'],
'UserData': '...', # Script de dados do usuário, se necessário
# Adicione outros parâmetros de configuração conforme necessário
}
# Criar Configuração de Lançamento
autoscaling_client.create_launch_configuration(**launch_config)
# Definir Grupo de Auto Scaling
auto_scaling_group = {
'AutoScalingGroupName': 'my-auto-scaling-group',
'LaunchConfigurationName': 'my-launch-config',
'MinSize': 2,
'MaxSize': 5,
'DesiredCapacity': 3,
'AvailabilityZones': ['us-east-1a', 'us-east-1b'],
# Adicione outros parâmetros do grupo, como verificações de saúde e políticas de escalonamento
}
# Criar Grupo de Auto Scaling
autoscaling_client.create_auto_scaling_group(**auto_scaling_group)
# Definir Elastic Load Balancer
elb_config = {
'LoadBalancerName': 'my-elb',
'Listeners': [
{
'Protocol': 'HTTP',
'LoadBalancerPort': 80,
'InstanceProtocol': 'HTTP',
'InstancePort': 80,
},
],
'AvailabilityZones': ['us-east-1a', 'us-east-1b'],
# Adicione outros parâmetros do ELB, como verificações de saúde
}
# Criar Elastic Load Balancer
elb_client.create_load_balancer(**elb_config)
# Anexar Grupo de Auto Scaling ao ELB
elb_client.register_instances_with_load_balancer(
LoadBalancerName='my-elb',
Instances=[
{'InstanceId': 'instance-id-1'},
{'InstanceId': 'instance-id-2'},
# Adicione IDs de instância do grupo de Auto Scaling
]
)
# Habilitar Balanceamento de Carga Entre Zonas
elb_client.modify_load_balancer_attributes(
LoadBalancerName='my-elb',
LoadBalancerAttributes={
'CrossZoneLoadBalancing': {
'Enabled': True
}
}
)
# Configurar Políticas de Auto Scaling
# Você pode definir políticas de escalonamento com base em métricas como utilização da CPU ou alarmes personalizados do CloudWatch
# Limpeza (por exemplo, quando você quiser excluir os recursos)
# Lembre-se de excluir o grupo de Auto Scaling antes da Configuração de Lançamento e do ELB
# autoscaling_client.delete_auto_scaling_group(AutoScalingGroupName='my-auto-scaling-group')
# autoscaling_client.delete_launch_configuration(LaunchConfigurationName='my-launch-config')
# elb_client.delete_load_balancer(LoadBalancerName='my-elb')
Certifique-se de substituir valores de espaço reservado como ‘ami-12345678’, ‘my-keypair’, ‘my-security-group’, ‘us-east-1a’, ‘us-east-1b’, ‘instance-id-1’, ‘instance-id-2’, etc., por valores apropriados para o seu ambiente AWS.
Este código demonstra a configuração básica de um grupo de Auto Scaling com uma Configuração de Lançamento e integração com um Elastic Load Balancer usando o Boto3, o SDK Python para AWS.
Perguntas de Entrevista Baseadas em Cenários
Cenário: Lidando com Picos de Tráfego
Pergunta: Como você configuraria o Auto Scaling para lidar com aumentos repentinos de tráfego na sua aplicação web? Resposta: Eu configuraria grupos de Auto Scaling com políticas de escalonamento apropriadas baseadas em métricas como utilização da CPU ou contagem de solicitações. Por exemplo, durante picos de tráfego, o Auto Scaling pode adicionar dinamicamente instâncias ao grupo para acomodar a carga aumentada. Eu garantiria que verificações de saúde estivessem configuradas para monitorar as novas instâncias lançadas e remover quaisquer instâncias não saudáveis automaticamente.
Cenário: Otimização de Custos
Pergunta: Explique como você otimizaria custos enquanto usa o Auto Scaling. Resposta: Para otimizar custos, eu configuraria grupos de Auto Scaling com contagens mínimas e máximas de instâncias apropriadas com base nos padrões de tráfego esperados. Além disso, eu aproveitaria recursos como Escalonamento Programado para ajustar a capacidade com base em padrões de tráfego previsíveis, como escalar para fora durante horas de pico e escalar para dentro durante horas de menor atividade. Usando AWS Cost Explorer e métricas do CloudWatch, eu monitoraria continuamente o uso de recursos e ajustaria as configurações de Auto Scaling conforme necessário para minimizar custos, garantindo ao mesmo tempo os requisitos de desempenho.
Cenário: Balanceamento de Carga Entre Múltiplas AZs
Pergunta: Como o Elastic Load Balancer distribui o tráfego de entrada entre várias Zonas de Disponibilidade (AZs) e por que isso é importante? Resposta: O Elastic Load Balancer distribui automaticamente o tráfego de entrada entre várias AZs para garantir alta disponibilidade e tolerância a falhas. Ele roteia o tráfego apenas para instâncias saudáveis dentro de cada AZ. Isso é crucial porque distribuir o tráfego entre AZs ajuda a prevenir interrupções de serviço devido a falhas em uma única AZ. O ELB monitora continuamente a saúde das instâncias e direciona o tráfego para longe de instâncias não saudáveis, contribuindo para a melhoria da confiabilidade da aplicação.
Cenário: Tratamento de Terminação SSL
Pergunta: Descreva como você trataria a terminação SSL com Elastic Load Balancer. Resposta: A terminação SSL envolve descarregar a descriptografia e criptografia SSL para o balanceador de carga, reduzindo o fardo computacional nas instâncias da aplicação. Para tratar a terminação SSL com ELB, eu configuraria certificados SSL para os ouvintes do balanceador de carga. O ELB descriptografaria o tráfego SSL de entrada, encaminharia-o para as instâncias backend via HTTP e criptografaria a resposta antes de enviá-la de volta ao cliente. Isso garante comunicação segura entre clientes e a aplicação, melhorando ao mesmo tempo o desempenho geral.
Cenário: Recuperação de Desastres
Pergunta: Como você garantiria recuperação de desastres e alta disponibilidade na sua configuração de infraestrutura? Resposta: Para garantir recuperação de desastres e alta disponibilidade, eu implementaria uma arquitetura multi-região com componentes redundantes em diferentes regiões da AWS. Isso inclui configurar grupos de Auto Scaling e Elastic Load Balancers em cada região para distribuir tráfego e carga de trabalho. Eu também replicaria dados entre regiões usando serviços como Amazon S3 e implantações Multi-AZ do RDS. Além disso, implementar configurações de failover ativo-ativo ou ativo-passivo para serviços críticos garante operação contínua mesmo em caso de interrupções em toda a região.
Cenário: Monitoramento e Alertas
Pergunta: Como você monitora e alerta sobre o desempenho do Auto Scaling e Elastic Load Balancer? Resposta: Eu uso extensivamente o Amazon CloudWatch para monitorar métricas de Auto Scaling e Elastic Load Balancer. Eu configuro alarmes do CloudWatch para disparar notificações com base em limites para métricas como utilização da CPU, latência de solicitação e saúde das instâncias. Para Auto Scaling, monitoro atividades de escalonamento, lançamentos e terminações de instâncias para garantir que o grupo esteja escalando adequadamente em resposta à demanda variável. Essas práticas proativas de monitoramento e alerta ajudam a identificar problemas de desempenho e garantir a confiabilidade e disponibilidade da infraestrutura.
Conclusão
O Auto Scaling com Elastic Load Balancer oferece uma arquitetura robusta e escalável para suas aplicações, garantindo alta disponibilidade e utilização eficiente de recursos.
Parabéns! Você deu um passo significativo em direção ao domínio do Auto Scaling na AWS. Amanhã, exploraremos outro aspecto crucial da computação em nuvem. Fique ligado!